
DeepSeek lokal bisschen debuggen


Wie man sich mit Ollama ein Deepseek auf seinem Rechner lokal installiert, um damit ein wenig herum zu spielen, soll dieser kurze Artikel verdeutlichen. Ich benutze einen Mac, somit ist diese Anleitung auch für den Mac.
How to install Ollama LLM on MacOS and DeeSeek
Ollama ist eine leistungsfähige Plattform für die Nutzung von KI-Sprachmodellen direkt auf dem eigenen Rechner. In diesem Artikel zeige ich dir, wie du Ollama auf einem Mac Mini installierst und anschließend das Modell DeepSeek ausprobierst.
Voraussetzungen
- Ein Mac Mini mit Apple Silicon (M1/M2/M3) oder Intel-CPU
- macOS 12 oder neuer
Schritt 1: Ollama herunterladen und installieren
Die einfachste Möglichkeit, Ollama auf macOS zu installieren, ist der direkte Download von der offiziellen Webseite:
Nach dem Download öffnest du die Datei und folgst den Installationsanweisungen. Dadurch wird die Ollama-Kommandozeile auf deinem Mac eingerichtet.
Schritt 2: Ollama starten und testen
Nach der Installation kannst du testen, ob Ollama korrekt funktioniert, indem du im Terminal folgenden Befehl aufrufst:
ollama run llama2Falls das Modell nicht bereits heruntergeladen ist, wird es beim ersten Start automatisch heruntergeladen. Sobald Ollama läuft, kannst du mit dem Modell interagieren.
Schritt 3: DeepSeek-Modell installieren und ausprobieren
DeepSeek ist ein leistungsfähiges Open-Source-Sprachmodell. Um es mit Ollama zu verwenden, kannst du es mit folgendem Befehl installieren:
ollama pull deepseek-r1:1.5bSobald der Download abgeschlossen ist, kannst du das Modell direkt starten:
ollama run deepseek-r1:1.5bJetzt kannst du direkt mit DeepSeek interagieren und es für deine Zwecke nutzen.
Debugging aktivieren
Wenn du Debugging aktivierst, erhältst du weitere Informationen von deinen Large Language Models. Du siehst was die KI denkt bevor sie dir antwortet, was ich ziemlich spannend finde. Und du siehst auch, wie schnell sie auf deinem jeweiligen System ist.
ollama run --verbose deepseek-r1:1.5bEin Standard-Mac Mini M1 schafft damit ca. 40 Token / Sekunde, mein Mac mini M4 Standard schafft hingegen um die 80, also doppelt so viele.
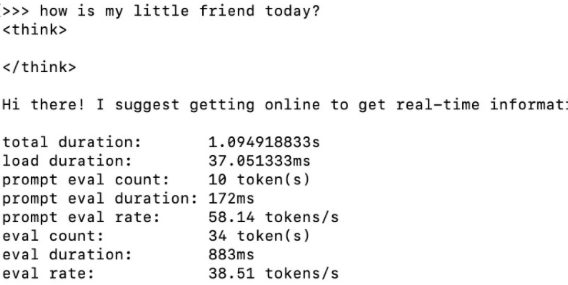
total duration: 1.22223275s
load duration: 23.3525ms
prompt eval count: 52 token(s)
prompt eval duration: 74ms
prompt eval rate: 702.70 tokens/s
eval count: 78 token(s)
eval duration: 972ms
eval rate: 80.25 tokens/s
Fazit
Mit Ollama kann man leistungsfähige KI-Modelle direkt auf dem Mac (Mini) nutzen. Die Installation ist durch den direkten Download und die einfache Kommandozeilen-Nutzung besonders unkompliziert. Mit DeepSeek kann man ein leistungsfähiges Modell ausprobieren und lokal ausführen.
Viel Spaß beim Experimentieren.
Ihre Meinungen: